저의 주관적인 해석이나 오역이 있을 수 있습니다. 댓글로 피드백 해주시면 수정하도록 하겠습니다!
https://arxiv.org/pdf/2404.07965.pdf
Abstract
기존의 사전학습 방법을 사용하는 언어 모델은 다음 토큰 예측 손실을 모든 훈련 토큰에 적용했습니다.
하지만 모든 토큰이 모델 훈련에 동일하게 중요하지는 않습니다.
저자가 토큰 레벨의 training dynamics of language model을 탐구 했을 때
토큰마다 다른 손실 패턴이 나타났기 때문에
저자는 RHO-1라는 새로운 언어 모델을 제시하고 있습니다.
RHO-1는 Selective Language Modeling을 사용하여 중요한 토큰을 이용해서 훈련합니다.
이러한 방식은 참조 모델을 사용하여 사전 학습한 토큰에서 초과 손실이 큰 토큰에 초점을 맞춰서 언어 모델을 훈련합니다.
1B OpenWebMath에 대한 사전훈련시에 RHO-1는 9개의 수학과제에서 최대 30프로의 few-shot 정확도를 향상 시켰습니다.
(few-shot 정확도 : 작은 특징을 분류하는 정확도를 나타낸다.)
pine-tuning on RHO-1_1B, _7B는 수학 데이터 셋에서 각각 40.6, 51.8의 결과를 냈습니다.
80B의 토큰으로 사전학습 되었을 때 RHO-1는 1개의 작업에서 평균 6.8% 향상을 달성해서
언어 모델 사전 교육의 효율성과 성능을 모두 향상 시켰습니다.

위 그래프는 보통의 언어 모델로 학습한 것보다 RHO-1로 학습한 것이 5~10배 더 빠르다는 것을 보여준다.
Introduction
파라미터와 데이터 셋의 크기를 확장하면서 LLM은 next token 예측 정확도가 지속적으로 상승하였습니다.
하지만 모든 사용 가능한 데이터로 훈련하는 것은 항상 최선이거나 실현가능하지는 않습니다.
결과적으로 heuristics와 classifiers을 사용해서 데이터를 필터링 하는 것은 중요합니다.
이 기술은 데이터의 품질과 모델을 성능을 향상 시킵니다.
하지만 문서수준의 필터링에도 불구하고 품질 높은 데이터셋은 많은 노이즈 토큰을 가지고 있습니다.
strict filtering으로 그런 토큰을 없애는 것은 텍스트의 의미를 변질시키고 편향적이게 할 수 있습니다..
또한 연구는 웹 데이터의 분포는 downstream application에 이상적인 분포와 일치하지 않는다는 것을 보여줍니다.
(downstream application : fine-tuning 방식을 이용해서 모델을 업데이트하는 것)
보통의 토큰 레벨의 말뭉치는 hallucination이나 예측하기에 애매한 유용하지 않은 내용을 담고 있고
같은 loss를 모든 토큰에 적용하면 유익하지 않은 토큰을 연산하고 제한된 LLM 잠재력을 가질 수 있습니다.
저자는 보통 사전학습중에 어떻게 토큰 레벨의 손실이 변화하는지를 보며 training dynamics를 검증해봤습니다.
각각의 checkpoints의 모델의 토큰의 perplexity를 평가하고 타입별로 토큰들을 분류했습니다.
이것으로 중요한 loss reduction은 선택된 토큰들의 그룹으로 국한된다는 것을 알게되었습니다.
많은 토큰들을 "easy tokens(이미 훈련된)" 이었고
몇몇 토큰들은 "hard tokens(가변적인 손실을 보이고 수렴하지 않는)"이었습니다.
이러한 토큰들은 비효율적인 gradient update로 이어질 수 있습니다.
이러한 분석을 토대로 저자는 RHO-1 모델을 추천합니다.
아래의 그림과 같이 이 접근법은 전체 sequence를 모델에 입력하고 선택적으로 유용하지 않은 토큰의 손실을 없앱니다.

자세한 pipeline 구조는 아래와 같습니다.

1. 좋은 품질의 말뭉치로 참조 언어모델을 훈련 시킨다.
- 이모델은 유틸리티 행렬을 생성한다. (원하는 분포로 토큰의 점수를 매긴다.)
2. 참조 모델을 사용해서 각각의 토큰을 손실를 통해 점수를 매긴다.
3. 참조모델에서 높은 초과 손실을 가지는 토큰들만을 사용해 훈련시킨다.
저자는 포괄적인 실험을 통해 SLM이 눈에 띄게 토큰의 효율성을 강화한다는 것을 보여줍니다.
또한 SLM은 효율적이게 토큰을 식별할 수 있습니다.
Selective Language Modeling
1. Not All Tokens Are Equal : Training Dynamics of Token Loss
보통의 사전 훈련에서 Tinyllama-1B with 15B token을 OpenWebMath로 사전학습하며
1B의 토큰 마다 checkpoints를 저장했습니다.
약 320000개의 유효성 검사 셋을 사용하여 1B 토큰마다 토큰 레벨의 손실을 평가 했을 때 아래와 같은 패턴을 보여줬습니다.

- 지속적인 고손실 (H->H)
- 증가하는 손실 (L->H)
- 감소하는 손실 (H->L)
- 지속적인 낮은 손실 (L->L)
이러한 분석에서 26%의 토큰이 중요한 손실 감소가 나타났고 (H->L)
51%의 토큰이 이미 훈련 되어있었고 (L->L)
11% 의 토큰이 지속적으로 challengin하였습니다. (aleatoric uncertainty이라고 예상된다. : 생성과정에서 발생한 불확실성)
두번째 관측에서 상당수의 손실들은 지속적인 변동이 있었고 수렴에 저항했습니다.
L->H, H->H의 토큰의 손실들은 아래의 그래프와 같이 높은 편차를 보였습니다. 이는 그 토큰들이 노이즈이고 그것은 저자의 가설과 일치한다고 합니다.


그러한 토큰들을 옆 사진과 같이 주황색으로 표시해 시각화 했을 때 명확하지 않은 말뭉치들로 보입니다. 예를 들어 사용자 정의 기호, 시간표, 참고 문헌과 같은 정보들이 이러한 토큰이 될 수 있습니다.
결과적으로, 각각의 토큰의 손실들은 전체의 손실같이 smoothly 감소하지 않는다는 걸 보여줍니다.
대신 각각의 토큰들에 복잡한 training dynamics이 존재합니다,
모델에 적합한 토큰들을 선택할 수 있다면, 모델의 훈련 궤적을 안정화시키고 효율성을 증가시킬 수 있다는 것입니다.
2. Selective Language Modeling
문서 수준의 필터링의 참조 모델의 관행에 염감을 받아, 저자는 간단한 pipeline of token-level data selection을 제시합니다.
그 방식은 위의 pipeline 그림과 같이 3단계로 이루어져있습니다.
1. 높은 품질의 데이터로 참조 모델을 훈련시킨다.
2. 참조 모델을 활용해서 각각의 토큰의 손실에 점수를 매긴다.
3. 언어 모델을 참조 손실과 비교해 높은 초과 손실을 토큰을 사용해 언어 모델을 훈련시킨다.
높은 초과 손실의 토큰은 더 훈련될만하고 원하는 분포와 더 많이 일치하기에
자연스럽게 불필요하거나 퀄리티가 낮은 토큰들은 제외됩니다.
Reference Modeling
먼저 high-quality dataset을 선별합니다.
참조 모델을 cross-entropy loss와 선별된 데이터를 통해 훈련시킵니다.
참조 모델의 결과를 이용해 큰 사전 훈련된 corpus의 토큰 손실을 계산합니다.
x_i : i번째 토큰
L_ref : 참조손실
x<i : i번째 이전의 모든 토큰
L_ref (x_i) = log P(x_i | x<i)
위 방식으로 selective pretraining의 참조 손실을 만들었습니다.
Selective pretraining
causal language modeling(CLM)은 cross-entropy loss를 사용합니다.
N : sequence의 길이
L_CLM(θ) : model θ로 매개변수화한 손실 함수
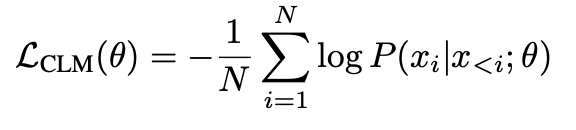
참조 모델에 비교해서 높은 초과 손실을 가진 토큰을 구하기 위해 손실의 차이를 구합니다.
L_Δ (x_i) = L_θ(x_i) - L_ref(x_i)
사용 토큰의 비율을 k%로 할 때 토큰의 초과 손실을 기준으로 사용할 토큰을 아래와 같이 정합니다.
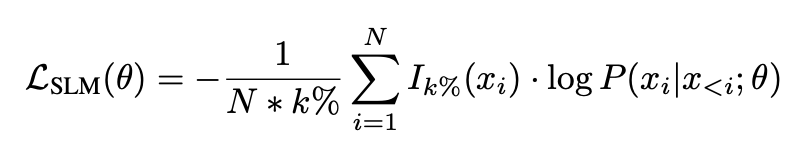
N * k% : 사용할 토큰의 개수

이러한 과정을 통해 언어 모델에 도움이 될 토큰들을 효과적으로 선별하고
그 토큰 들로만 학습을 진행합니다.
Discussion and Future work
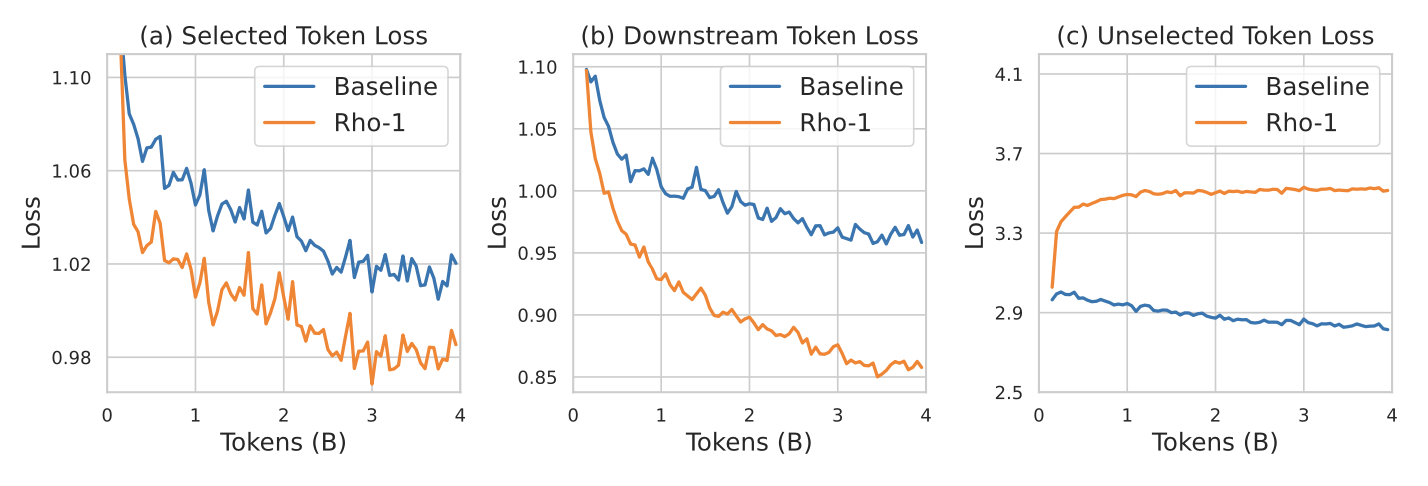
위 표와 같이 수학 연속 사전 훈련에서 SLM으로 훈련하면 참조 모델에 초점을 맞춘 도메인에 빠르게 수렴되고
선택하기 않은 토큰의 손실은 크게 증가합니다.
이러한 손실 증가로 인한 부정적인 영향은 아직 찾을 수 없었으며 일반적인 사전 훈련 손실은 overfitting을 방지할 수 있습니다.
Scalabiliy
이 논문에서는 예산 부족으로 인해 7B 이하의 파라미터를 가진 작은 모델과
100B 이하의 데이터를 가진 작은 데이터셋을 가지고만 효과를 입증했습니다.
작은 모델들에서는 필요 없는 토큰의 손실을 무시하고 중요한 것에 집중하는 중요한 이점을 가집니다.
저자는 미래엔 SLM은 큰 모델과 데이터에 적용할 수 있다고 예상하고 있습니다.
is Training a reference model necessary?
토큰에 점수를 매기기위해 좋은 품질의 참조 모델이 필요합니다.
이것은 작은 양의 좋은 품질의 데이터로 훈련될 수도 있고 오픈 소스 모델을 사용할 수도 있습니다.
여기선 input logprobs나 perplexity가 필요한 것이기 때문에 강력한 독접 모델 api를 사용할 수 있습니다.
API에 토큰을 넣고 반환되는 log probabilities를 사용할 수 있습니다.
How to improve upon SLM?
선택하는 대신 토큰의 weight를 재조정하면서 모델의 정확성을 증가시킬 수 있습니다.
overfitting을 줄이기 위해 많은 참조 모델을 사용할 수도 있습니다.
Expanding the use of SLM
SLM은 많은 SFT 데이터 셋의 노이즈, 분포 불일치를 해결하기 위해 미세조정으로 확장 될 수 있습니다.
또한 저자는 잠재정 응용분야로 정렬을 꼽고 있습니다.
이 논문은 파라미터와 데이터셋의 크기를 늘리는 것말고 선택적인 토큰 사용을 통해 훈련을 더욱 효율적이게 진행하고
성능을 향상 시킬 수 있다고 말하고 있습니다. 인공지능 구현에서 모델을 설계하는 것 많은 데이터를 수집하고
중요하기에 SLM을 통해 더욱 효율적으로 데이터를 사용할 수 있는 방법을 제시한다는 점에서 흥미로운 논문이었습니다.
'Deep Learning' 카테고리의 다른 글
| Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets 논문 리뷰 (0) | 2024.04.01 |
|---|---|
| 손으로 마우스 조종 with Mediapipe (0) | 2024.01.10 |
| Recurrent Neural Network in Tensorflow (2) | 2024.01.07 |
| Convolution Neural Network in Tensorflow (0) | 2023.12.15 |
| Gradient descent algorithm in Tensor flow 경사하강법 (0) | 2023.11.05 |